Have you ever assumed that if it’s not safe to drink the tap water while travelling, then you must rely on single-use bottled water?
We did…
But the great news is this is no longer the case. Better options exist and smart, responsible travellers around the world are seeking them out.
Here are some insights to help you join your fellow travellers in giving single-use plastic bottles the flick.
We are not finanically or otherwise affiliated with any of the products or services mentioned in this blog.
Sri Lanka hydration guide
At the start of our Sri Lanka trip the number of plastic bottles we were consuming was growing at an alarming rate. We thought there must be a better way. And there was!
There are actually numerous clean water sources (some more obvious than others) that allowed us to significantly reduce our plastic bottle waste.
Personal purifier
Before getting into Sri Lanka’s network of water refill stations, a quick note on personal filter and purifier options. If you’re planning ahead for longer term or regular travel, having your own water purifier bottle or system can be great to cover your hydration needs. We now use “Travel Tap” water purifying systems which is very versitile and convenient, and there are plenty of other choices available.
But if you don’t have one of these magical water purifiers, never fear. Check out our tips below for staying hydrated in Sri Lanka without leaving a trail of plastic pollution behind you.
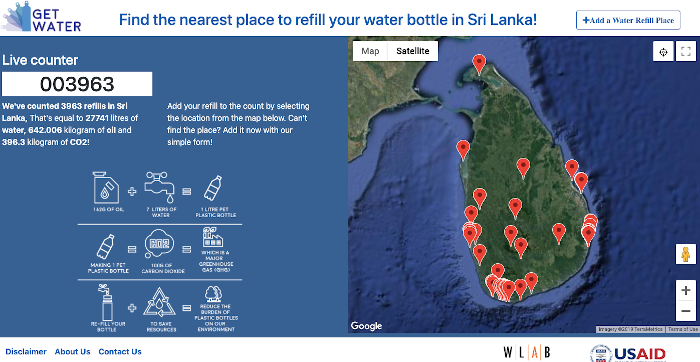
GetWater.Lk
GetWater.lk documents the network of water refill station options around Sri Lanka to help travellers avoid single-use bottles. You can check out Get Water’s website and use their nifty map to find water refill options near you. You can also contribute by adding additional clean water refill treasures that you discover during your travels.
Many of the places we found to re-fill our bottles weren’t yet recorded by Get Water. With this in mind, it’s definitely worth asking and looking around if Getwater.lk doesn’t show options near you. And if you find new options, add them!
Below we share with you just few of the many places and ways to refill, and things learnt along the way about water in Sri Lanka.
Arugambay
Waste Less ABay
On the main street in Arugambay you will find a free purified water refill station called WLAB. You can also drop off pastic water bottles for recycling there! It was actually WLAB who started the Getwater.lk initiative mentioned above!
Restuarants - Spice Trail & others
Find refreshing cold water served in a re-fillable glass bottle at restaurants like Spice Trail on the main road through Arugambay (picture of menu below).
Sigiriya
There are at least two free purified water re-fill stations in Sigiriya installed by Pina Organization, one in the Village (on Sigiriya Rd outside Central College) and one inside the main (western) entrance to Lion Rock.
How we discovered this
We first stumbled across a water station outside the school in Sigiriya Village. We took our bottles and refilled them before visiting Lion Rock. But we could have saved the extra walk because on arrival to Lion Rock we discovered another refill station specifically for tourists inside the entrance! Hopefully it is only a matter of time before these are more widely publicised.
Anuradhapura
You can actually refill at many of the local general stores in town for only 3 LKR per litre. Who knew?! A 1.5 litre plastic bottle costs between 70-150 rupees, so only 3 LKR per litre is quite a saving!
The photo below shows the kind of water tank to look for. This particular place was located on Niwanthaka Chethiya Road, Anuradhapura.
How we discovered this
We asked our excellent guest house, Heritage Lake View, if they had a verified clean water line like some other places. Our host said that wasn’t available at the property, and told us he re-fills his water drums in town for 3 LKR per litre. He took us to the general store to re-fill our water that afternoon (on our way to sightseeing) and even lent us one of his 7 litre drums to use during our stay.
So an easy option is to ask your accommodation where to refill, or if you can refill from their clean water supply (depending on the situation, you could offer a small amount to cover water costs, although this is usually not expected).
I’d tap that!
A note on “tap water”:
Not all tap water in Sri Lanka is created equal. While you can’t drink from just any tap, most accomodation and restaurants in certain areas actually have a special water line providing safe drinking water. It’s generally referred to as a “Government” or “Water Board” water line. Technically it comes out of a tap but it is not standard “tap water”. It is a potable water line verified by the Sri Lankan Water Board.
This was a big surprise to us. We started asking our accomodation if they had a Government water line. Often they did and were happy to refill our bottles for us. We understand some travellers may be wary. Ultimately you must assess the risk for yourself, but we drank a lot of Government line water without any issues, including in Trincomalee, Galle and Mirissa.
Below we share some information about water in Trincomalee and the South Coast, including some Government water line and filtered/mineral water options. (Some areas in Sri Lanka rely more heavily on ground water, which we understand varies in quality from place to place. We did not happen to drink ground/well water so do not comment further on this here.)
Trincomalee
Verified clean water lines are installed at most accomodation and restaurants in the area. Ask your accomodation if you can use their Government water line to re-fill your bottle.
The water tasted good and we had no issues. It is important to ask otherwise restaurants/accomodation tend to assume tourists whould rather single-use plastic bottles.
Sometimes we find it helps to explain we are trying to use less plastic to avoid leaving plastic pollution behind us when we travel. Our hosts have been very responsive to this and happy to accomodate this request! But if a host is reluctant or doesn’t understand our request, of course we respect that too.
How we discovered this
It was actaully a beachfront restaurant owner who first told us about this. He was concerned about plastic pollution, as were we, and he told us most properties in the area have at least one verified clean water line. A what in the who know?! How did we not know about this?! He went on to tell us that this was locally called a ‘sofia line’ (or something sounding like that!) after the french water company that installed the water infrastructure. We asked our accomodation (Sea Zone Hotel) and sure enough they had a line and showed us where to refill our bottles with clean, safe drinking water! There were separate water lines to the guest bathrooms (which are not safe for drinking) and there was only one drink safe ‘sofia line’ available outside and another one in the kitchen. The hotel owners told us it was mandatory for them to have that water line.
At Pedlar’s Inn Cafe and Restaurant we noticed Sri Lankan people had glasses of water on their table so asked the waiter for the same. We’re not sure if it was from the Government water line or mineral water, but it tasted fine and quenched our thirst.
Our experience is that reputable establishments in Sri Lanka have water sanitation practices in place to prepare food, fresh juices etc. After enjoying drinks like Lime Juice that clearly had added water, we started to trust that water served at these venues would also be fine. And after 6 weeks and counting travelling in Sri Lanka, so far so good!
Unawatuna Beach, Galle
Hideout
The hideout cafe and restaurant offers free purified mineral water refills for patrons. We thoroughly enjoyed the tacos, burritos and bountry cake here too! If you just need water, we’re sure they would happily refill your bottle, maybe for a small fee.
Mirissa
We asked our friendly hosts at our Homestay (Sun Ray Rest) to use their Government / Water Board line for drinking water. They were very obliging and refilled our bottles for us. If you are open to trying this option, definitely ask your accomodation about it!
Dickwella / Hiriketiya Beach
Stay at Peak house for all your filtered water needs! We enjoyed the water filter here so didn’t need water from the Government line, however the host told us that most properties in the area do have a Government water line.
Verse Collective is trendy space in Dickwella that provides table water in re-fillable glass bottles rather than plastic. It has solid wifi too!
Winning the water game
Time to blow this single-use bottled water myth right out of the water!
Smart and experienced travellers around the world are seeking out alternatives to unnecessary and harmful single-use plastics. Forward thinking businesses and organisations are already offering solutions. Others are still developing the awareness and resources to do so.
So, now you know, join your fellow travellers in kicking the single-use plastic habit. Support organisations offering solutions and let locals know you want to help keep their country beautiful and ocean life healthy by not leaving a trail of plastic waste behind you.
Travel App feature?
Would you find it useful if patforms like Trip Advisor, Booking.com, Google Maps, AirBNB etc listed “water re-fill station” as a facility at the accomodation/restaurant/area? If so send them some direct feedback or let us know in the comments below to help get this added as a feature!
While using the tips shared here we have stayed healthy and never experienced any water related health issues in Sri Lanka. However, of course we cannot absolutely guarantee the quality of any drinking water supply.
In this blog we share our path to applying US-centric All-Weather investment information to an Australian situation, with the result being a global All-Weather portfolio. This is by no means advice, rather we share our experience in case it is interesting or useful to others and to further develop our ideas. We embarked on this because our current situation necessitated reducing our investment timing risk and an “All-Weather” approach could smooth out the ride.
Our story - discovering “All-Weather” investment & why we wanted in
We (Amy and Dan) are a couple in our early 30s, just married, and enjoying the flexibility of renting without a house mortgage. Until 2018 we invested almost 100% of our (modest) savings in a portfolio of equities (aka. shares/stocks) - following advice given to people with long time-horizons to invest savings heavily in equities, preferably by dollar cost averaging, to maximize returns over the long run. We were happy to take on the risk of equities until we decided we might want to buy a house in the next 5 years and realized our equity investment time-horizon wasn’t so long-term after all.
We knew from the stock market’s history that our life-savings could quickly plummet in value and take years to recuperate. We didn’t want this to happen at the same time we planned to use our savings for a house deposit! So we started selling our equities and by the start of 2019 most of our savings were sitting in a cash savings account.
The problem was that it could be awhile before we actually purchased a house and we had a nagging sense that our savings should be doing more for us in the meantime. We no longer want the risk of being almost 100% in equities but we also aren’t happy holding mainly cash since any other asset class will provide more returns than cash over time. And we definitely weren’t interested in trying to time the equity market. So what to do?
When we heard about Bridgewater Associates’ “All-Weather” strategy to minimize downturns in any economic environment while outperforming cash this seemed like an elegant solution. Living in Melbourne with its reputation for four seasons in one day we’ve learnt to either be prepared for surprise changes in weather or face the consequences! [queue Four Seasons In One Day by Aussie band Crowded House]. The “All-Weather” analogy struck a chord and we thought having an investment portfolio designed to weather any economic storm would be awesome for our situation!
The next question was how? There is no way we could afford the hedge fund giant’s minimum buy-in for their All-Weather fund, and the fund is closed to new investors anyway, so this was not an option. We looked around but couldn’t find anyone offering a suitable All-Weather style fund that we could access. So we decided to build one ourselves.
Fortunately, in 2014 the founder of Bridgewater Associates, Ray Dalio, shared his recommended asset types and weights for a very simplified version of All-Weather that an average person could implement themselves, in an interview with life/business strategist Tony Robbins. This helped us to get a sense of what our portfolio might look like. But because the advice was targeted at US citizens, we weren’t sure if it was directly applicable to us (as Australians) or how to practically implement it.
Our problem - how do we apply US-centric All-Weather advice to our Australian situation?
But first, a brief background on what is an All-Weather portfolio?
What is an All-Weather portfolio?
“If you can’t predict the future with much certainty and you don’t know which particular economic conditions will unfold, then it seems reasonable to hold a mix of assets that can perform well across all different types of economic environments. Leverage helps make the impact of the asset classes similar.” (from Bridgewater’s The All-Weather Story)
All-Weather is an approach to asset allocation designed to minimize downside and perform relatively well regardless of the prevailing economic environment, hence the name “All-Weather”. The concept was first implemented by Ray Dalio and his team at Bridgewater Associates, now the largest hedge fund in the world. In researching and developing All-Weather, Bridgewater recognized there are primarily two factors driving the value of any asset class - the levels of economic activity (growth) and inflation. Therefore, the economy can be broadly viewed as having four “environments”. These are:
Throughout history and across countries, distinct asset classes have consistently performed well during each of these four environments. So, there is a season for all assets, but unlike the real weather we never know which seasons are next or when the seasons will change, and worse, two seasons can occur at once! So surprises impact asset prices due to unexpected rises or falls in growth and inflation.
Recognizing this, an All-Weather portfolio essentially comprises four sub-portfolios - one for each economic environment containing assets known to perform well in that environment. Asset weights are then balanced to achieve risk-parity between each of the four environments. Bridgewater’s diagram below shows the four economic environments containing examples of relevant asset types, with risk divided equally across environments.
The All-Weather approach assumes we can’t forecast the future so we don’t know which particular growth/inflation conditions will unfold. Given this, it assigns weights such that there is an equal amount of risk (25%) in each of the 4 possible growth/inflation environments. Therefore the portfolio is designed to perform no matter which growth/inflation environment eventuates.
All-Seasons portfolio
As mentioned above, Tony Robbins popularised a simplified version of Dalio’s All-Weather, coined the “All-Seasons” portfolio in his 2014 book MONEY Master the Game: 7 Simple Steps to Financial Freedom. Robbin’s has also published a free version of the Ray Dalio All-Weather interview in this Yahoo Finance article which is worth a read.
In a nutshell, the Dalio/Robbins All-Seasons portfolio looks like this:
30% stocks
40% US long-term treasury bonds (20-25 years)
15% US intermediate-term treasury bonds (7-10 years)
7.5% gold
7.5% commodities
All-Seasons vs Bridewater’s All-Weather - what’s the difference?
An important point to clarify is that All-Seasons is NOT the same as Bridgewater’s All-Weather. Bridgewater uses cheap leverage and sophisticated investment instruments to increase returns while still minimizing risk. The simplified All-Seasons portfolio does not use leverage and thus has lower expected returns than Bridgewater’s All-Weather, but still reduces risk.
Throughout this article, we use the term “All-Weather” to convey the general concept of diversified, risk-balanced asset allocation developed by Bridgewater outlined above, acknowledging that All-Weather portfolios that utilise leverage appropriately, like Bridgewater do, will outperform non-leveraged versions. See the Q and A section below for more commentary on using leverage in a risk balanced investment strategy.
As an aside, we’re still working on figuring out how the average individual investor in Australia can cost-effectively leverage the lower volatility assets (e.g. Treasury bonds) to have similar expected volatility/returns as equities, thus maintaining risk parity while increasing returns, like Bridgewater can. One way might be through Treasury bond futures. But we need to iron out how to achieve this practically in a cost effect way. If you have the answer, let us know!
So, we set out to understand how to create our own All-Weather portfolio(s) without using leverage, for now.
Our solution - domestic and global portfolios
We wanted a globally diversified All-Weather portfolio. We achieved this by creating essentially two sub-portfolios - an All-Weather portfolio containing Australian domestic assets, and another All-Weather portfolio containing global assets for geographic diversification. First, we’ll share how we developed the domestic portfolio. Then we’ll delve into the global portfolios.
Click here to skip straight to our table of portfolios showing individual securities and weights.
Domestic
The All-Seasons portfolio outlined by Robbins’ has a domestic bent, comprising US stocks and government bonds (ie treasuries). We wanted exposure to both Australian and Global asset markets.
The relevant global ETFs available on the Australian Securities Exchange (ASX) exclude Australian assets (ie are “ex AU”). Therefore to have exposure to Australian and global markets it was necessary to include these securities separately (see the Q and A section below for more commentary on this).
Scroll down to Table 2 and for example portfolios that select one security from each asset type.
Table 1.Relevant securities for asset types in an Australian domestic “All-Seasons” portfolio.
Asset type
Relevant securities via ASX / unlisted fund
Equities
Vanguard Australian Shares Index ETF (VAS); BetaShares Australia 200 ETF (A200); BetaShares Australian Sustainability Leaders ETF (FAIR); Vanguard Index Australian Shares Fund (VAN0010AU)
Long-term Australian treasury bonds (~20-25 yrs)
Long-term exchange-traded treasury bonds (ETBs): - year of maturity - 2037 (GSBG37); - year of maturity - 2039 (GSBK39); - year of maturity - 2041 (GSBI41); - year of maturity - 2047 (GSBE47)
Intermediate Australian treasury bonds (5-10 yrs)
Vanguard Australian Government Bond Index ETF (VGB); BetaShares Australian Government Bond ETF (AGVT); iShares government bond index ETF (IGB)
We understood that the underlying principles of the All-Weather approach are timeless and universal and therefore would apply in Australia (and globally). But we weren’t sure whether the asset class proportions recommended for the US All-Seasons would be the same in Australia. So we (particularly the data scientist among us) wanted to test it out on plenty of historical data before trusting it with our life savings. To sense test, we first looked at historical performance using the All-Seasons asset weights for both US and Australian assets.
back-test the resulting portfolio weights to assess historical returns and more importantly, drawdowns, in terms of their size, duration and frequency.
Experimenting with different assets through this algorithm gave us comfort that the asset weightings recommended for the US are generally applicable in Australia (and globally). Since Bridgewater uses IL-bonds and EM credit in their All-Weather strategy, and since we can access these via the ASX and have an algorithm enabling us to risk-balance them, we also added IL bonds (and EM credit for global) to our versions of the All-Weather. Historical performance plots in Figure 1, using Australian domestic assets, shows that “our version” does a very good job of avoiding downturns compared to 100% equities/ASX300.
For sure, Figure 1 shows the overall return of 100% equities (ASX 300 accumulation) was the highest, but it also shows one could have put money in/taken it out of All-Seasons and Our Version at any time since 2001 without suffering unpalatable losses. This is what we are currently after! The same can not be said for 100% equities/ASX300 which, on four occasions between 2001 and 2019, suffered drawdowns large enough to be unacceptable for our current situation.
Domestic Australian All-Seasons and Our Versions of the asset mix protect capital, with less frequent and smaller drawdowns than the ASX 300
Figure 1. Historical performance simulations of domestic Australian “All-Seasons” and “Our Version” portfolios show these portfolios had considerably smaller and less frequent drawdowns compared to 100% equities via the ASX 300 acummulation index. The relevant securities and weights for each of these portfolios are shown in Table 2. ETFs for the required asset classes were not available prior to 2012 so the pre-2012 performance shown is based on their underlying indexes. Historical bond performance was derived from futures price indices with coupon payments accumulated semi annually at historical 10 year yield rates. The commodities performance reflects underlying SPGCLEP commodities index only, excluding potential ETF distribution payments. We painstakingly sourced this historic index data from a variety of free sources and can’t guarantee its accuracy - if anybody reading this has access to a proprietary data source they’d like to share with us, please get in touch! Note these simulated results do not include brokerage fees and assumes the desired portfolio balance is maintained throughout, whereas in practice, the portfolio would be rebalanced periodically (e.g. every 6 months or so). Simulated historical performance results have inherent limitations since unlike an actual performance record, simulations do not reflect the cost of trading or the impact of actual trades on market factors such as volume and liquidity. See the Q and A section below for commentary on periodic rebalancing.
Lower risk comes with lower expected returns We’re not suggesting our simple All-Weather portfolio is optimal or will maximize returns. It almost certainly won’t. Rather, it is designed to protect assets by avoiding large drawdowns during economic upheavals and market downturns, while still providing reasonable returns above the cash interest rate. In our current circumstance the security of knowing we are less exposed to downturns is worth the decreased expected return potential.
Global
A limitation we saw of a domestic Aussie portfolio was a lack of geographical diversity. To get more exposure to global activities and therefore hopefully more resilience to economic surprises, we made a second All-Weather portfolio using global assets. (For more on the benefits of geographical diversification, including for All-Weather, see Bridgewater Associates’ April 2019 memo.)
We used Dan’s algorithm to create All-Weather risk parity weightings for global assets and back-test them. We used historic data from ETFs available on US securities exchanges for this task because they have existed for longer than their Australian ETF counterparts and therefore have more data.
This process meant we identified ETFs available on US securities exchanges that can be used to create a global All-Weather portfolio. We also included US only stocks and government bonds in the mix because the US-exchanged global shares and bond ETFs exclude US stocks and bonds. For completeness we’ve included these securities in Table 2 under columns “Global (NYSE/ NASDAQ)” and “Global with IL-bonds (NYSE/ NASDAQ)”.
Out of curiosity we added inflation-linked bonds to our Global (NYSE/ NASDAQ) portfolio. But given we could not find a global IL bond ETF on the ASX, we chose not to include IL bonds in our Global (ASX) portfolio. Of course it would be possible to access a Global IL bonds ETF via an international trading platform, but at this point we wanted to stick to ASX traded global securities to reduce complexity.
The historical performance plot in Figure 2 below shows that our Global version also does well at avoiding downturns compared to a 100% global equities allocation. Again, 100% equities gives a higher return, but our current time-horizon and needs favour limiting drawdowns over maximising returns.
Our Global asset mix protects capital during turbulence with less frequent and smaller drawdowns, compared to 100% Global Equities
Figure 2.Historical performance simulations of “Our Version” of an unleveraged global All-Weather portfolio show it had lower returns but also considerably smaller and less frequent drawdowns compared to 100% “Global Equities”. The relevant securities and weights for each of the portfolios depicted here are provided in Table 2. Note these simulated results do not include brokerage fees and assumes the desired portfolio balance is maintained throughout, whereas in practice, the portfolio would be rebalanced periodically (e.g. every 6 months or so). Simulated historical performance results have inherent limitations since unlike an actual performance record, simulations do not reflect the cost of trading or the impact of actual trades on market factors such as volume and liquidity. See the Q and A section below for commentary on periodic rebalancing.
Table 2.Relevant securities and their weights for each of the portfolios represented by the historical performance plots: All-Seasons (Domestic Australia), Our Version including IL Bonds (Domestic Australia), Our Version (Global-ASX), Our Version (Global-US NYSE/NASDAQ), Our Version including IL bonds (Global-US NYSE/NASDAQ). Historical performance simulations of these portfolios versus 100% equities are shown in Figure 1 and Figure 2. A short description for each ticker is provided in Table 3 below.
Asset type
All Seasons Domestic Aus (ASX)
Our Version Domestic Aus (ASX)
Our Version Global (ASX)
Our Version Global (NYSE/ NASDAQ)
Global with IL-bonds (NYSE/ NASDAQ)
Equities
30% VAS or FAIR
24% VAS or FAIR
20% VESG; 3% VGE
10% VEA; 11% VTI; 3% EEM
9% VEA; 11% VTI; 2% EEM
Emerging market credit
-
-
13% IHEB
12% EMB
10% EMB
Long-term treasury bonds (~20-25 yrs)
40% GSBK39 &/or GSBI41 &/or GSBE47*
25% GSBK39 &/or GSBI41 &/or GSBE47*
-
27% TLT
19% TLT
Intermediate treasury bonds (~7-10 yrs)
15% IGB
15% IGB
51% VIF
22% BWX
23% BWX
Inflation linked bonds
-
24% ILB
-
-
10% TIP; 5% WIP
Gold
7.5% PMGOLD
6% PMGOLD
7% GOLD
8% GLD
6% GLD
Commodities
7.5% QCB
6% QCB
6% QCB
7% DBC
5% DBC
Note on long-term treasuries in Australia: Of note is that we could not find any ETFs on the ASX that tracked long term (~20-25 years) Australian treasury bonds. We found only individual exchange traded long-term treasury bonds (ETBs). These ETBs have lower liquidity than the ETFs which can make it difficult to buy and sell when desired. Because of this we considered not using long-term bonds at all. But since Dalio recommended including long-term bonds because they provide higher returns than intermediate (due to higher volatility), we decided to give the ETBs a go. Increased bond volatility and returns was particularly important to us since we have not yet figured out how to leverage up the volatility and returns of our bond holdings in a cost effective way.
Table 3.Description and Exchange for each security listed in the Table 2. It’s worth noting that BetaShares Australian Sustainability Leaders ETF (FAIR) provides an ethical/sustainable Aussie equities option, and Vanguard Ethically Conscious International Shares Index ETF (VESG) provides an ethical/sustainable Global equities option, we found these really interesting.
Ticker
Exchange
Description
BWX
NYSE
SPDR Barclays International Treasury Bond
DBC
NYSE
Invesco DB Commodity Index Tracking Fund
EEM
NYSE
iShares MSCI Emerging Markets ETF
EMB
NASDAQ
iShares JP Morgan USD Emerging Markets Bond ETF
FAIR
ASX
BetaShares Australian Sustainability Leaders ETF
GLD
NYSE
SPDR Gold Shares
GOLD
ASX
ETFS Physical Gold (non-hedged)
GSBE47
ASX
Exchange-traded Treasury Bond – maturity 2047
GSBG37
ASX
Exchange-traded Treasury Bond – maturity 2037
GSBI41
ASX
Exchange-traded Treasury Bond – maturity 2041
GSBK39
ASX
Exchange-traded Treasury Bond – maturity 2039
IGB
ASX
iShares government bond index ETF
ILB
ASX
iShares Government Inflation ETF
IHEB
ASX
iShares J.P. Morgan USD Emerging Markets Bond (AUD Hedged) ETF
Vanguard Ethically Conscious International Shares Index ETF
VIF
ASX
Vanguard International Fixed Interest Index ETF (Hedged)
VGE
ASX
Vanguard FTSE Emerging Markets Shares ETF
VEA
NYSE
Vanguard FTSE Developed Markets ETF
VTI
NYSE
Vanguard Total Stock Market ETF
WIP
NYSE
SPDR FTSE International Government Inflation-Protected Bond ETF
Closing Remarks
In the hope it may be interesting or useful to others, we’ve shared our experiences of realising we had to switch our time-horizon from long- to medium-term when thinking about investing, and that an “All-Weather” approach could help us do this. We’ve also shared our path to overcoming the problem of how to apply US-centric All-Seasons/All-Weather advice to an Australian situation using both domestic and global assets - the result being a globally diversified All-Weather portfolio. We do not comment on what percentage should be allocated to domestic vs global assets, however we do discuss this further in the Q and A section.
It’s worth noting that if our personal situation was different, say already owning a house and not needing to draw on our savings for the next 20 years, we may just keep dollar cost averaging our savings into low cost passive equity index funds. But that’s not the case for us right now.
Also, we are not trying to convince anyone in any situation to take our approach. We know a lot of people are interested in All-Weather, and we are simply sharing our own process and experience in building these portfolios in case it is interesting/beneficial to others, and also to clarify and develop our own thinking. To be clear, we are not qualified in finance - our backgrounds are data science/neuroscience, and law/environmental sustainability.
But we’ve enjoyed finding a solution to protect our assets’ value during any economic environment in case we want to draw on it at any time. We hope our approach will tame the rollercoaster that comes with the usual bull-runs and drawdowns when entirely in equities (see Figure 3 below), and also decrease our discomfort if there is another big down-turn like 2008.
We plan to keep refining our All-Weather portfolios / approach as time permits, hopefully finding practical ways to a) leverage the low volatility assets up to the level of equities’ volatility thus maintaining our All-Weather risk balance while increasing our expected returns, b) include global IL bonds in our ASX based global portfolio, c) add more ESG compatible assets, d) improve the code in our all-weather-risk-parity repository to allow it be used for any country (pull-requests with improvements/additions welcome if any devs. are reading this!), and e) research whether or not there is a place for crypto currencies to be added into our All-Weather asset mix. So much to do, so little time! But we’ll see how we go.
Figure 3.For illustration purposes (read for the lulz) only may not reflect reality!
Questions & Answers
As we were trying to understand Bridgewater’s All-Weather principles, some obvious questions occurred (and were flagged) to us, which are addressed below.
Of course, we cannot comprehensively cover everything here. If you’re after a deeper understanding, we recommend reading Bridgewater Associates’ 2015 article ‘Our thoughts about Risk Parity and All Weather’, which addresses common questions and misconceptions about risk parity and All-Weather.
Question: Is the All-Weather asset allocation based on past correlations between assets, which are unstable/unreliable going forward?
Answer: No, because:
The asset allocation is not based on the correlations between assets.
Rather, the portfolio is created based on the relationships of assets types to their environmental drivers. (There are four environmental drivers – economic growth, economic decline, inflation and deflation.)
While asset classes offer a risk premium that is similar once adjusting for risk, their inherent sensitivities to shifts in the economic environment are different.
Therefore, we can structure a portfolio of risk adjusted asset classes so that their environmental sensitivities reliably offset one another, leaving the risk premium as the driver of returns.
Question: Wouldn’t leveraging the bonds (or other less volatile assets) increase the risk of the portfolio?
Answer: No, because:
The leverage makes the volatility of your bonds’ equal to your equities and thus gives better diversification than possible without leverage. “For example, if I put 50% of my money in an unleveraged Treasury bond and 50% of my money in stocks, my portfolio would have been dominated by stocks during the 2008 financial crisis because stocks are more volatile; however, if I leveraged my bonds to have the same volatility as stocks, I would have had much better diversification and would have had much lower risks during the financial crisis.” (Bridgewater’s Engineering Targeted Returns and-Risks)
We wouldn’t need to use too much leverage, for example Bridgewater’s All-Weather strategy is only around 2 times leveraged.
Question: Is being Australian (earning and spending Australian dollars etcc) a good reason to run an Australian-only portfolio? Given Australia is such a small market compared to the rest of the world, wouldn’t it be better to come up with a currency hedging strategy to overlay across a global portfolio?
Answer: This is an important question in relation to portfolio diversification.
A desire to have geographical diversification was the reason we created a global All-Weather portfolio. The reasons for our approach to develop both the domestic and global portfolios separately are two-fold:
First, it was simpler to apply the All-Weather principles to domestic and global separately because global All-Weather asset allocation is more complex than domestic only. Our limited resources and reliance on global index funds means our global risk weightings are less precise. This is in part because we cannot control the exact weightings the index funds use across countries. For example, the global stocks ETF is geographically weighted differently to the global bonds ETF.
Second, the global ETFs traded on the ASX exclude Australian assets (ie are “ex AU”), therefore to have exposure to Australian markets it is necessary to include these securities separately.
Although we have noted that geographical diversification is important (see relevant Bridgewater Associates 2019 article and Vanguard Australia 2017 article on benefits of international diversification), we have not commented on how we think assets should be allocated across the Australian vs Global assets because it is a thorny issue. For example, if we were to allocate assets based on Australia’s market cap within global indices, we would only have about 3% Australian assets and the rest (97%) would be global. However, Vanguard Australia’s research shows that Australians tend to have a strong home bias when investing in shares. In 2014, Australians collectively held 66.5% Australian shares in their share portfolio, despite Australia representing only approximately 2.5% of the global market at that time. Robin Bowerman, Head of Corporate Affairs at Vanguard Australia comments that ‘home-bias investing ranks among the biggest forms of under-diversification’ (see Bowerman’s article). We have found that we are not completely immune to this ‘home bias’, even though we are aware of the problem!
According to Aidan Geysen, Senior Investment Strategist and Manager with Vanguard’s Investment Strategy Group, there are numerous reasons investors prefer home equities, some of which are behavioural and some that have sound investment rationale, including ‘a preference for the familiar, ease of access, aversion to currency risk, tax benefits and liability hedging to name a few’ (see Geysen’s article). Along with all information included in our article, we leave the reader to form their own view on what geographical asset allocation is most appropriate.
Question: How does your algorithm arrive at the target weights for the various asset classes?
Answer: The algorithm takes as input the users’ desired assets which the user has already pre-assigned into their relevant “environments” in this ‘portfolio-settings.yaml’ file (e.g. stocks go in the ‘rising growth’ and the ‘falling inflation’ environments because that’s when they tend to do well, IL-bonds assigned to the ‘rising inflation’ and ‘falling growth’ environments, etc). The algorithm then:
creates weights for risk-parity of the assets within each environment, essentially creating 4 “sub-portfolios”, a sub-portfolio for each environment. Then,
it looks at the overall volatility of each sub-portfolio and creates risk-parity weights between each of the 4 sub-portfolios so each takes on 25% of the risk. Then,
each asset’s final weight is determined by the sum of [its within environment weights]-multiplied by-[its overall environment weights], and the final ticker weight is output. The within- and between-environment risk-parity calculations are performed with the help of a python version of Ze Vinicius and Daniel Palomar’s ‘riskParityPortfolio’ package.
Question: How do you know when and by how much to rebalance the portfolio weights. Is this based on the prevailing growth and inflation environments? If so wouldn’t it require a measure and also a forecast for growth and inflation?
Answer:
This passive All-Weather approach assumes we can’t/won’t forecast the future so we don’t know which particular growth/inflation conditions will unfold. Given this, it assigns weights such that there is an equal amount of risk (25%) in each of the 4 possible growth/inflation environments. Therefore the portfolio is designed to perform no matter which growth/inflation environment dominates.
Regarding the question of when/how much to rebalance: how much is easy because we simply rebalance so our portfolio weights are back in line with the target weights already determined by the All-Weather risk-parity algorithm. These target weights shouldn’t change much year-to-year as they should be arrived at using many year’s historical volatility data. Each additional year of volatility data has small effect on overall volatility estimates.
But when to rebalance depends on how happy we are to let the weights drift considering brokerage costs. In this article on a simplified version of Ray Dalio’s All-Weather, Robbins recommends rebalancing the All-Seasons “at least annually” and notes that “if done properly, this can actually increase tax efficiency”. People’s tax situations vary so we don’t comment on a tax strategy here.
If a big financial upheaval, like in 2008, occurs in the middle of our usual rebalancing interim, it may be worth rebalancing prematurely. But assuming our portfolio weights are still within a few % of the targets weights (we’d assign some arbitrary threshold, say <10% abs. overall unbalance) there should be limited need to rebalance outside our chosen interval.
Question: What about including crypto currencies like BitCoin?
Answer: We could certainly consider adding crypto currencies like BitCoin into an asset mix, if we had good reasoning and evidence to decide in which of the four environments it should do well. But we have not yet done any research to confirm. We plan to research this in the future.
Want to know more about Bridgewater’s All-Weather investment strategy? See their articles:
Wow, it’s been 2 years since I last wrote a blog post. Since then I finished work as a neuroscientist and started a data science job at SEEK. Loving the career change, I’m working in the AI platform services team where I use machine learning (ML) to help improve the efficiency of employment markets. I’m lucky to be surrounded by some excellent experienced data scientists and engineers and have learnt many useful skills. I plan to start blogging again to share some of the useful things I’ve picked up over the last 2 years.
One of the most useful and versatile tools I’ve picked up to help data science workflow is Docker.
What’s so good about using docker for interactive data science?
The thing I love about using docker is, it has eliminated the hassle of re-installing software and managing package/library/module versions every time I want to train ML models on a different machine – no more fighting module conflicts! You can make a docker image that has all your favourite data science tooling, and then use that image to easily build a container with your data science work environment that is identical every time, no matter what machine you build it on.
So no more “it worked when I ran it on my machine”!! ;-P
Some basic terminology
Dockerfile:
The ‘dockerfile’ is a text file with simple code that describes your docker image.
Docker image:
The docker ‘image’ describes the base operating system and all the other programs you want (for example, in my case: linux, R, dplyrpython, fastText, xgboost, PyICU etc).
Docker container:
A running instance of an image is called a ‘container’. You can have one or many containers of the same image running on one or many physical host machines.
For want of an analogy… analogies are rarely perfect and this one is no exception, but in terms of baking a cake:
the dockerfile is your ingredients list,
the image is your recipe,
the container is the cake!
And the machine you are using is the oven.
You can bake as many cakes as you like with a given recipe. You can bake the exact same cake many times in different ovens. You can bake multiple cakes simultaneously in the same oven. As long as a machine has docker installed, your docker image is going to run and the container will work the same every time!
Test installation worked by running the simple hello-world Docker image:
in your terminal/command prompt docker run hello-world
To start with, you may like to use an pre-made public image created for data science tooling, pulled directly from dockerhub. There are many of these available for free for on dockerhub which as a nice search function.
I made this docker image to help with my data science work flow. Specifically it allows me to quickly and easily set up the required versions of my tooling/packages (python3.6, R, dplyrxgboost, fastText, pyICU etc.) in a container on other machines.
The image can be pulled as is from directly from my public docker repo using terminal command:
docker pull danielpnewman/training-tools
Alternatively you can update my docker files and rebuild your own custom image using the steps below. :-)
Making your own docker image, ideal for model training using Python3.6, xgboost, fastText, PyICU, R, dplyr, and any other data science tools you like:
If needed update the Dockerfile with required software.
If needed update requirements with required python packages.
Build local docker image from Dockerfile in ~/training-docker-files directory, this code tags the image name as “danielpnewman/training-tools”, which can be changed to whatever name you like:
cd training-docker-files
docker build -t danielpnewman/training-tools .
Put training data, scripts etc. into local /to-mount directory and then mount it into the docker container when you build it using this command:
docker run --interactive --tty --volume $(pwd)/to-mount:/training/to-mount danielpnewman/training-tools
Note you can mount multiple directories:
docker run --interactive --tty --volume $(pwd)/to-mount:/training/to-mount --volume $(pwd)/scripts:/training/scrips danielpnewman/training-tools
You can close the terminal of an active docker session and then log back into it later using its CONTAINER ID, e.g:
- exec -it d40b2796e7ca /bin/bash
Very basic docker cheat sheet
List Docker CLI commands
dockerdocker container --help
Display Docker version and info
docker --versiondocker versiondocker info
Execute Docker image
docker run hello-world
List Docker images
docker image ls
List Docker containers (running, all, all in quiet mode)
docker container lsdocker container ls --alldocker container ls -aq
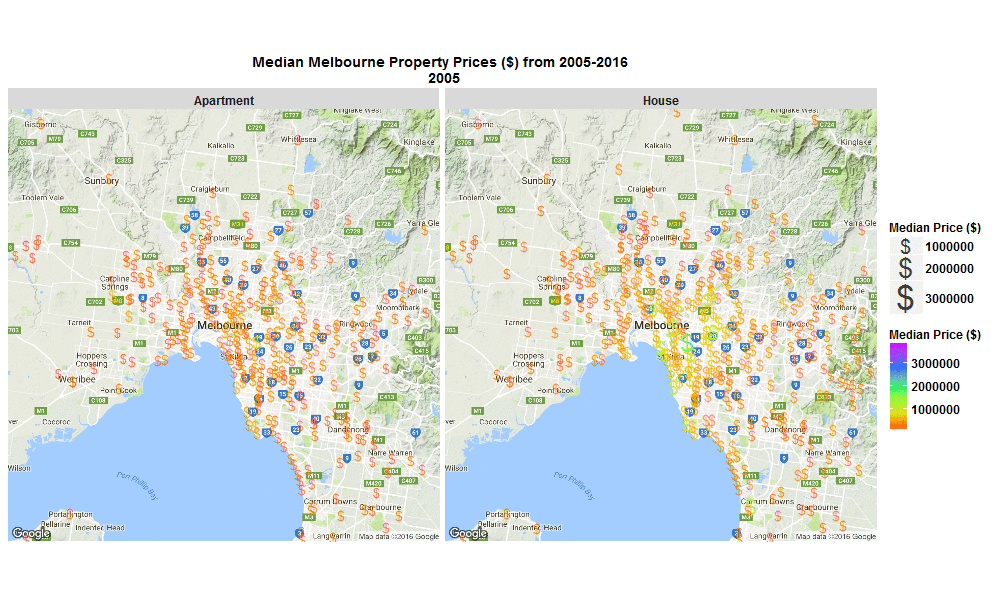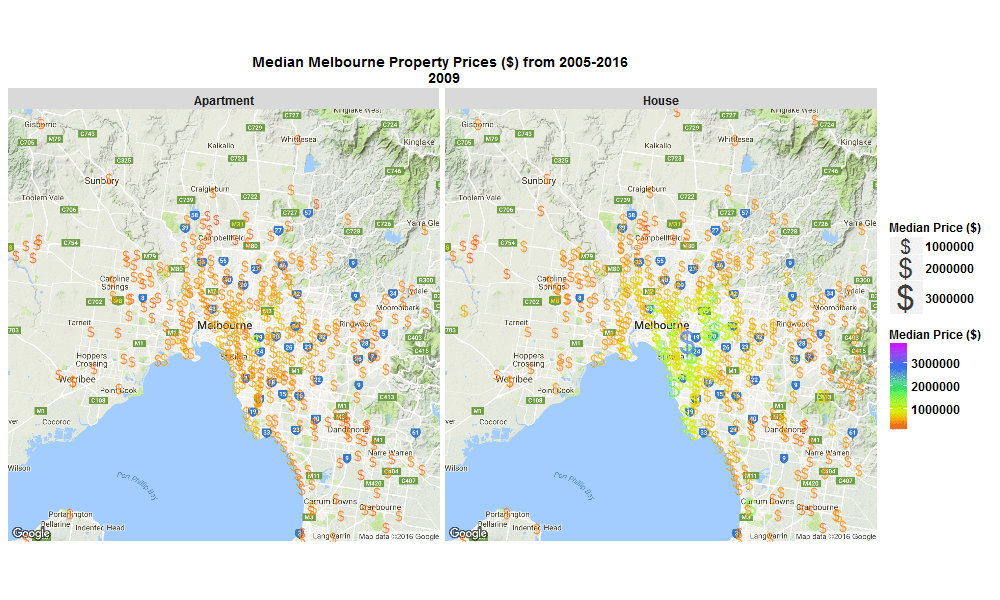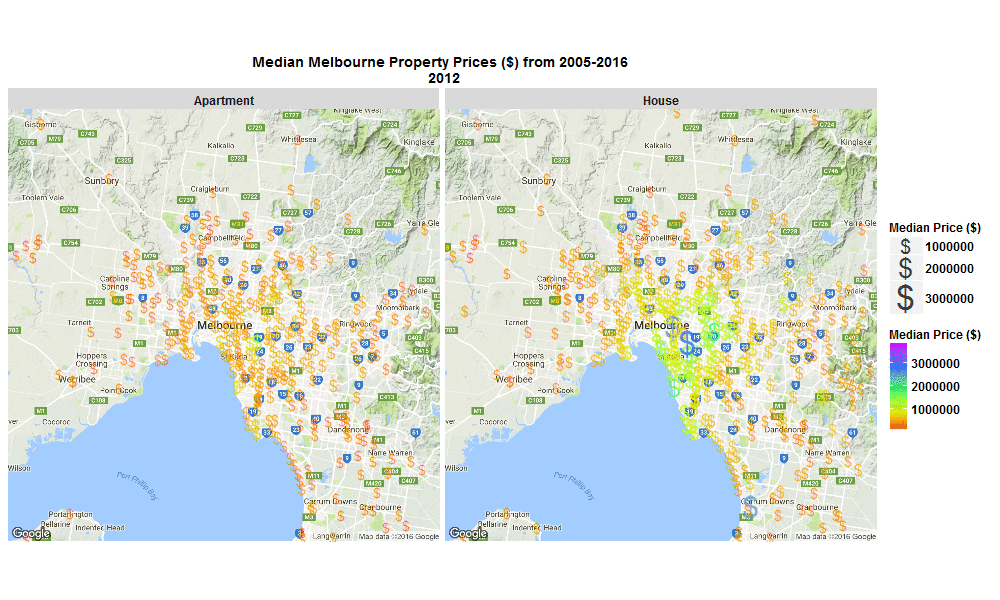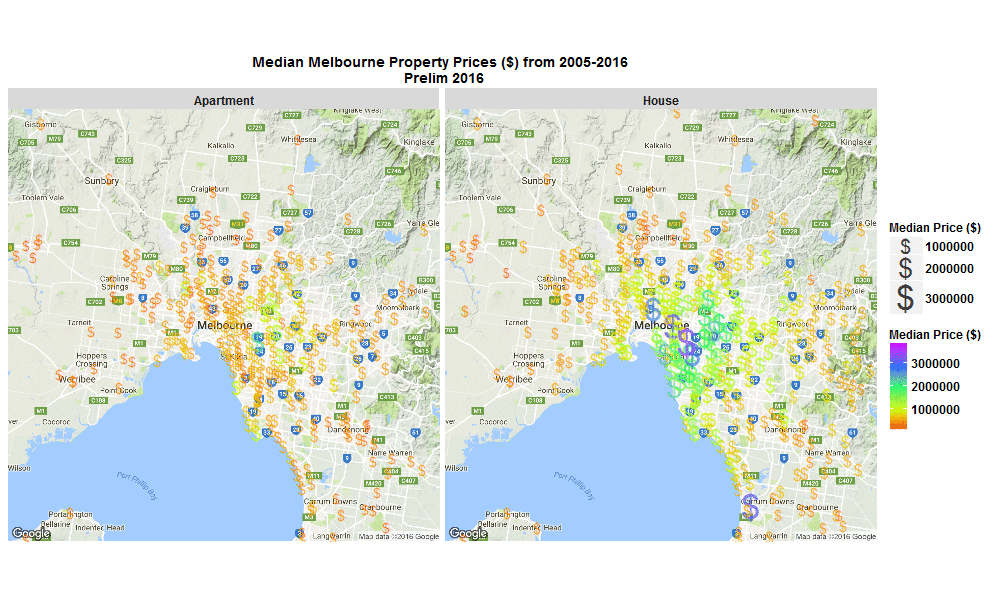
A few weeks back I made a blog post with this nice little .gif below, of change over time in Median Melbourne Property Prices ($) from 2005-2016 - see my previous blog on 29 Sep 2016 :
Well I’ve just come back to looking at that data set and this time I’ve plotted the % change per annum and overall, and also absolute $ change from 2005-2016 on some interactive plots.
These plots allow you to zoom in, hover over a suburb to see more info, or click on a suburb to open a new window and explore that suburb in more detail.
The R code I used to make the plots below is here.
Explore below, it’s interesting to see that SYNDAL has the greatest per annum and overall % growth, however it’s TOORAK that has by far has the highest absolute $ growth over the same period of time.











 Image
Image  Image taken from Bridgewater’s
Image taken from Bridgewater’s  Figure 1. Historical performance simulations of domestic Australian “All-Seasons” and “Our Version” portfolios show these portfolios had considerably smaller and less frequent drawdowns compared to 100% equities via the ASX 300 acummulation index. The relevant securities and weights for each of these portfolios are shown in
Figure 1. Historical performance simulations of domestic Australian “All-Seasons” and “Our Version” portfolios show these portfolios had considerably smaller and less frequent drawdowns compared to 100% equities via the ASX 300 acummulation index. The relevant securities and weights for each of these portfolios are shown in  Figure 2. Historical performance simulations of “Our Version” of an unleveraged global All-Weather portfolio show it had lower returns but also considerably smaller and less frequent drawdowns compared to 100% “Global Equities”. The relevant securities and weights for each of the portfolios depicted here are provided in
Figure 2. Historical performance simulations of “Our Version” of an unleveraged global All-Weather portfolio show it had lower returns but also considerably smaller and less frequent drawdowns compared to 100% “Global Equities”. The relevant securities and weights for each of the portfolios depicted here are provided in  Figure 3. For illustration purposes (read for the lulz) only may not reflect reality!
Figure 3. For illustration purposes (read for the lulz) only may not reflect reality!